Policy Guard¶
Lifecycle components to guard and enforce policies (or instructions) in LLM responses.
Overview¶
Policy Guards are post-inference components that can be used to guard for and reinforce policies on LLM responses. A policy can be any statement or instruction that describes a constraint on an LLM response. For example: "The response must be in JSON format" or "The response should not include any hyperboles".
A policy guard takes as input an LLM response and a set of policy statements and produces an output depending on its configuration:
- Detect Guard: The guard checks whether the LLM response follows the policy and outputs "Yes/No" along with an explanation.
- Detect+Repair Guard: The guard detects and repairs any policy violations in the LLM response; it outputs a rewritten and repaired version of the response.
Detect and Repair are LLM-based and follow a specific strategy. The middleware components in this repo support the following detect and repair strategies:
Detect Strategies¶
- Batch: all input policies are checked in a single LLM inference
- Single: input policies are checked one at a time in a series of LLM inferences
Repair Strategies¶
- Batch: the response is rewritten once to repair a set of policy violations in a single LLM inference
- Iterative: the response is iteratively rewritten by repairing one policy violation in each iteration.
- Retry: retry repeatedly attempts to batch repair the response until no more violations are detected or the maximum number of retries has been reached.
- Best-of-n: best-of-n samples n batch repairs using temperature and selects the repaired sample with the fewest number of detected violations.
- MapReduce: in the map phase, repaired versions of the LLM response are generated independently for each detected policy violation. During the reduce phase all repaired versions are merged into a single repaired version.
Experimentally, Best-of-N yields the strongest results with the best repair rate. Batch is the most cost-effective strategy as it requires only a single LLM inference for repair.
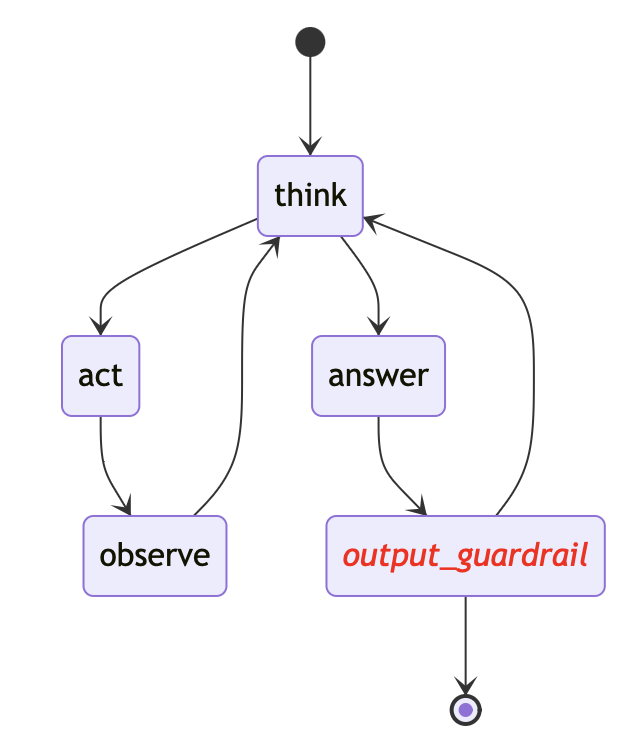
Architecture¶
The answer is passed to the output guardrail block to enforce policy guardrails.
Results¶
We evaluated policy guards by measuring the increase in the policy compliance rate that can be achieved with Policy Guards over simply adding the policy statements as instructions in the prompt.
We used a derivative of the popular IFEval dataset, where we treated instructions as policy statements and scaled the number of instructions added to a query up to ten instructions. We then measured the policy compliance rate as the instruction following (IF) rate without and with policy guards with using various strategies.
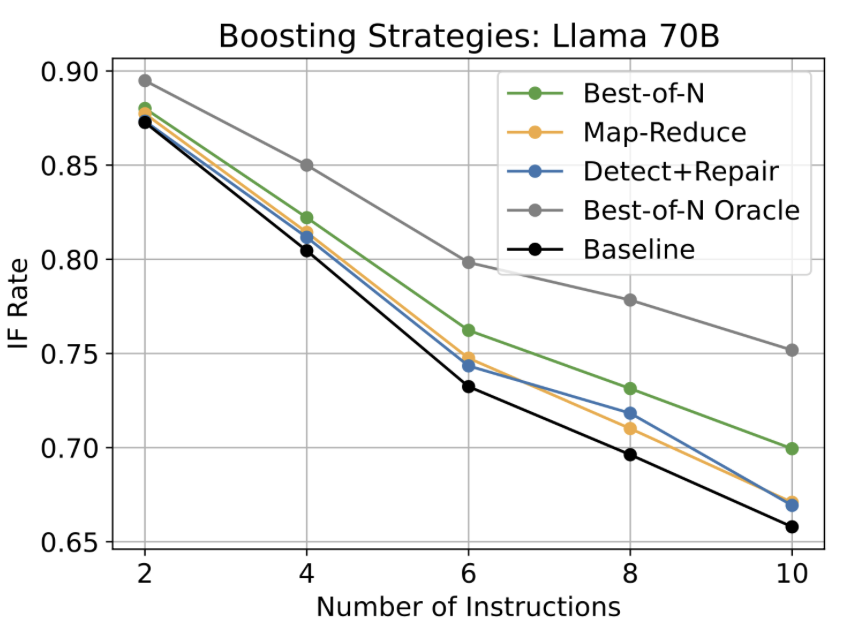
In the above figure baseline refers to only adding the instructions to the prompt and Detect+Repair refers to the Batch repairer above. The above figure shows the achieved instruction following (IF) rates for the four strategies using Llama 3.1 70B. The IF rate achieved by only adding the instructions to the prompt is shown as the baseline. Detect+Repair in the figure above refers to the Batch repairer. All repair strategies lead to IF rate improvements over the baseline. Even at two instructions, policy guards lead to small improvements and the benefits generally increase with the number of instructions. Best-of-N policy guards consistently provide the largest improvements, up to 4 percentage points at ten instructions, increasing the IF rate to 0.70 from 0.66. Best-of-N Oracle refers to a version where we used an oracle detector to select the best of the N generated version to illustrate the potential IF rate achievable through Best-of-N policy guards. Even at two instructions, the model is capable of generating repaired responses with an IF rate of 0.89, a 2 percentage point increase. The boost grows as instructions are increased to ten, when the IF rate reaches 0.75, an 8.5 percentage point increase.
Additional results are reported in [1].
Getting Started¶
When to Use This Component¶
There are two primary use cases for policy guards:
- Reinforce a priori guidelines or policy on LLM output; for example, policy guards can be installed as for specific requirements (e.g., "response should be in table format"), best practices (e.g., "include a personal opening in the email") or constraints ("do not include confidential information")
- Improve or correct agent responses; for example, if, in spite of including an instruction in the prompt to follow a certain format, say JSON, th agent generates incorrect output, a policy guard can be installed as a corrective agent to enforce a desired behavior.
However, policy guards incur an additional cost and should only be installed when guideline/policy compliance is a priority.
Quick Start¶
To illustrate the use of policy guards this folder includes a sample file with LLM responses and policies and a script that shows how to run a policy guard on the LLM responses.
examples/sample_responses-llama-policies-10.jsonl: a file with 100 data samples where each data sample consists of a query and ten policy statements derived from the IFEval, dataset, as well as LLM responses that were generated with Llama-3.1-70b.examples/run_altk_pipeline.py: python script to illustrate how to use the policy guard detect and repair components
To run the python script use the following:
> python run_altk_pipeline.py --input_file sample_responses-llama-policies-10.jsonl --output_file ouptut.json --verbose
The script will produce an output file with detection and repair results.
To see all commandline options use:
Ready to get started?¶
Go to our GitHub repo and run this example or get the code running by following the instructions in the README.
References¶
[1] Elder, B., et al., "Boosting Instruction Following at Scale," arXiv preprint arXiv: (2025). https://arxiv.org/abs/2510.14842